These days, most employees work with data, regardless of their role—but they’re not necess...

These days, most employees work with data, regardless of their role—but they’re not necess...
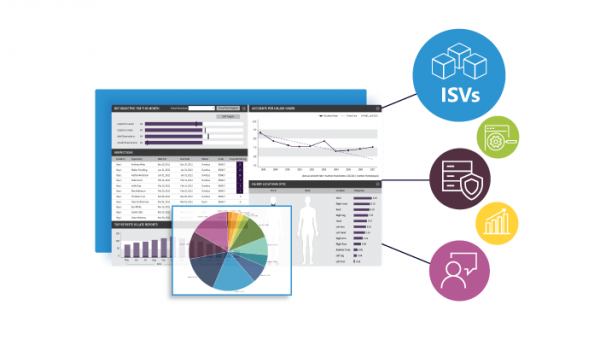
The past few years have demonstra...

Self-Service analytics is all the rage these days; IT departments don't want to be the per...

Whether it comes in the form of an interactive dashboard on your computer screen or a mult...

For years companies have been using data to identify trends, uncover insights and gain com...
_thumbnail.png)
It’s all about protecting your data and enabling enterprise-wide adoption of data analytic...

A new collection of nuggets to amp up your analytics business.
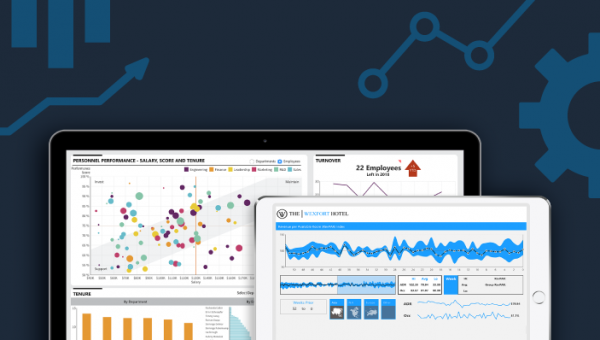
When it comes to using a Business Intelligence (BI) platform, typically, a company will fa...

It's time to stop thinking about Business Intelligence as a cost, rather than a way to sav...
Augmenting products and services with analytics can help to monetize your data.

Everyone probably has more relationships in their data than they realize.

The essential last step of any successful data-driven analytics strategy.
Follow Us
Support