Background
The Pareto Chart is a unique visualization in that it contains both bars and a line graph, where individual values are represented in descending order by bars, and the cumulative total of those values is represented by the line from left to right. For instance, the line begins at the top of the first bar, and as we move right, towards the second bar, the line displays the combined total of both bars as a percentage, representing the total share of these 2 items (i.e. products) out of the entire group of items. Upon reaching the final bar, the line’s total will always be equal to 100%, representing the cumulative percentage share of all the bars (items).
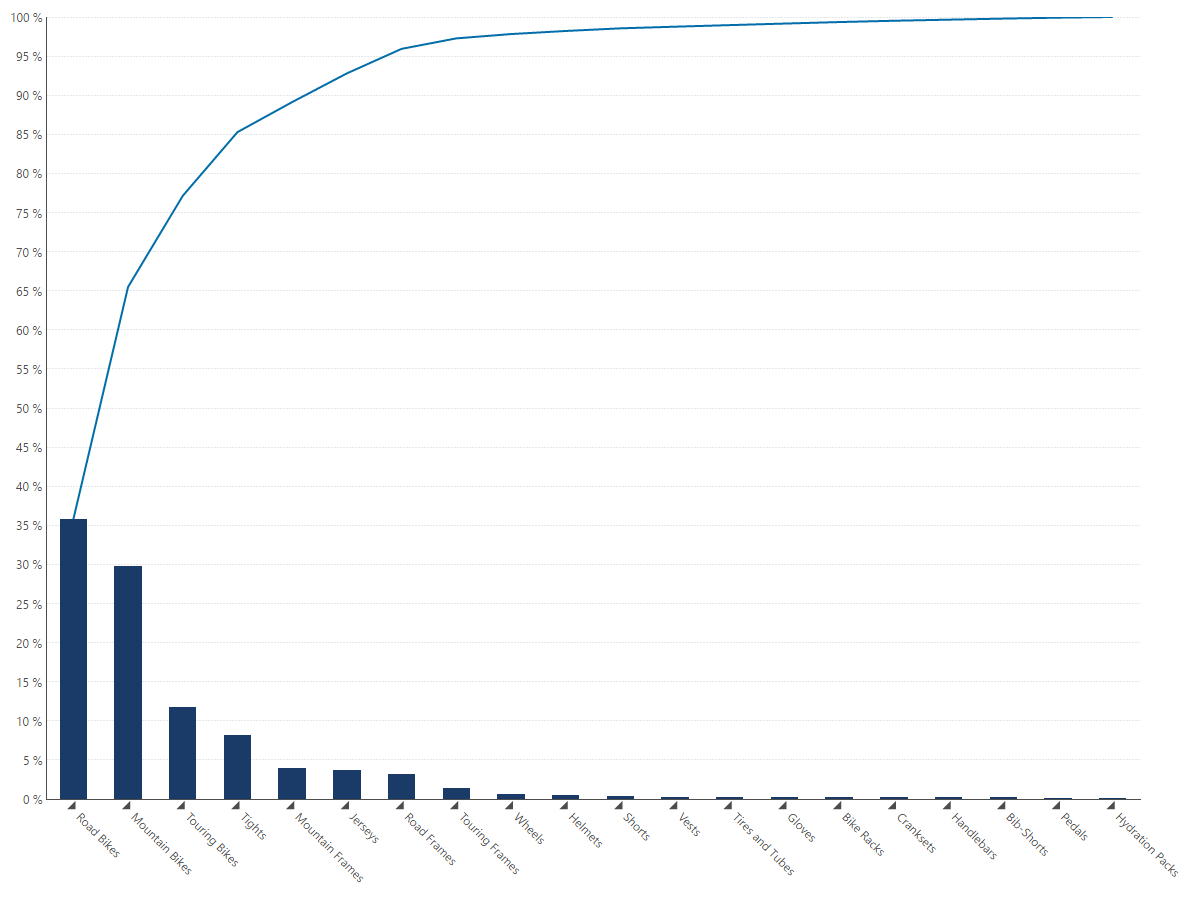
Figure 1 - Example of a Pareto Chart created in Dundas BI
The chart is a derivative of the Pareto principle, which states that, for many events, roughly 80% of the effects come from 20% of the causes. This principle is named after Italian engineer, Vilfredo Pareto, who observed that 80% of the land in Italy was owned by 20% of the population. The principle was further developed, as Vilfredo observed that roughly 20% of the peapods in his garden contained 80% of the peas.
The Pareto Chart, derived from a histogram, views causes of a problem in order of severity from largest to smallest, ultimately demonstrating the Pareto principle. With a Pareto Chart, you are able to highlight the most important among a large set of factors. The most prevalent use case is for quality control, be it identifying the most common source of defects, the highest occurring type of defect, the most frequent reason for customer complaints, and so on. However, this visualization can easily be applied to other events, such as business, where 80% of profits are regularly elicited from 20% of products.
Use Case
As noted, Pareto Charts are not used solely for the purpose of quality control. Many natural phenomena have been shown empirically to exhibit such a distribution. For example, we can use a Pareto Chart to hypothesize, based on the Pareto principle, that the frequency by which a word occurs in a novel is a strong representation of what or whom the story is centered upon.
Using public data from Emil Johansson’s Lord of the Rings project, I’ve compiled a list of the 26 most referenced characters in J.R.R. Tolkien’s, The Hobbit, along with the number of times each character was referenced.
Before displaying this data set in a Pareto Chart, I’m going to visualize it as a Pie Chart. The purpose of this exercise, is to explain that although Pie Charts are often a common choice to visualize the share distribution of categories, there are many instances where they are far less effective in displaying this information.

Figure 2 - Pie Chart created in Dundas BI, visualizing the frequency by which a character is referenced
Research has found that it is extremely difficult for people to accurately discern the differences between 2-dimensional areas, such as pie slices, as opposed to comparing lengths, such as the lengths of bars. It is also difficult to accurately identify which slices reference which category, as the viewer must constantly alternate from viewing the legend and the chart. Matters are made more difficult, as with large numbers of categories, the differences in slice colors are often very subtle.
Now, let’s re-visualize the same data set, in a Pareto Chart.
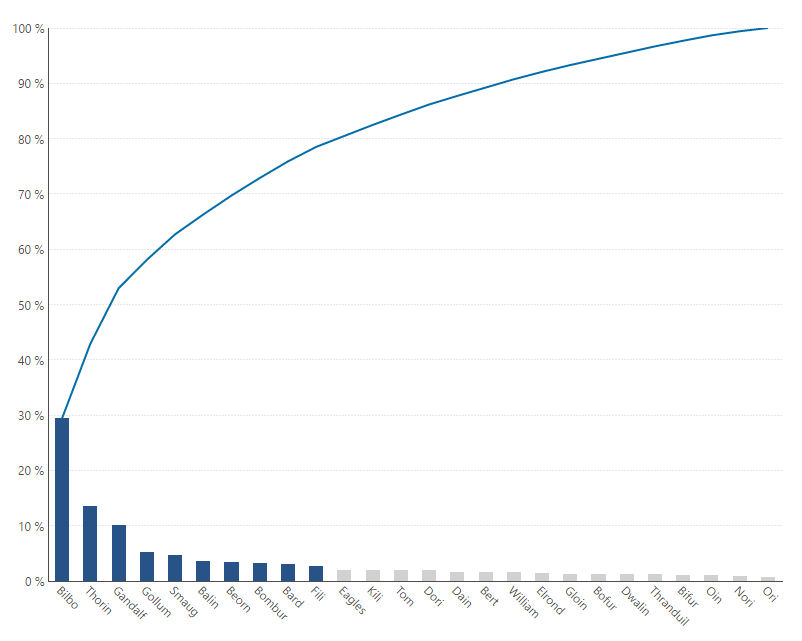
Figure 3 - Pareto Chart created in Dundas BI, visualizing the frequency by which a character is referenced
At a glance, this tells us a number of things. The bars/columns show the occurrence of an event (in this case, the frequency by which characters are referenced), while the line shows the cumulative percentage. The Pareto Chart very clearly emphasizes the relative sizes of each value, as opposed to the Pie Chart. We are also able to instantly identify which characters have been referenced the most (Bilbo, Thorin and Gandalf), which allows us to focus on the most important categories (thus differentiating between the ‘vital few’ and the ‘trivial many’).
Our final image, is the same Pareto Chart above, however it has been zoomed-in, to reflect the 6 most referenced characters. This chart also includes a ‘tooltip’, where upon hover, the user can easily understand the total quantity of a value, the percent of the total that the value pervades, and its cumulative percent.
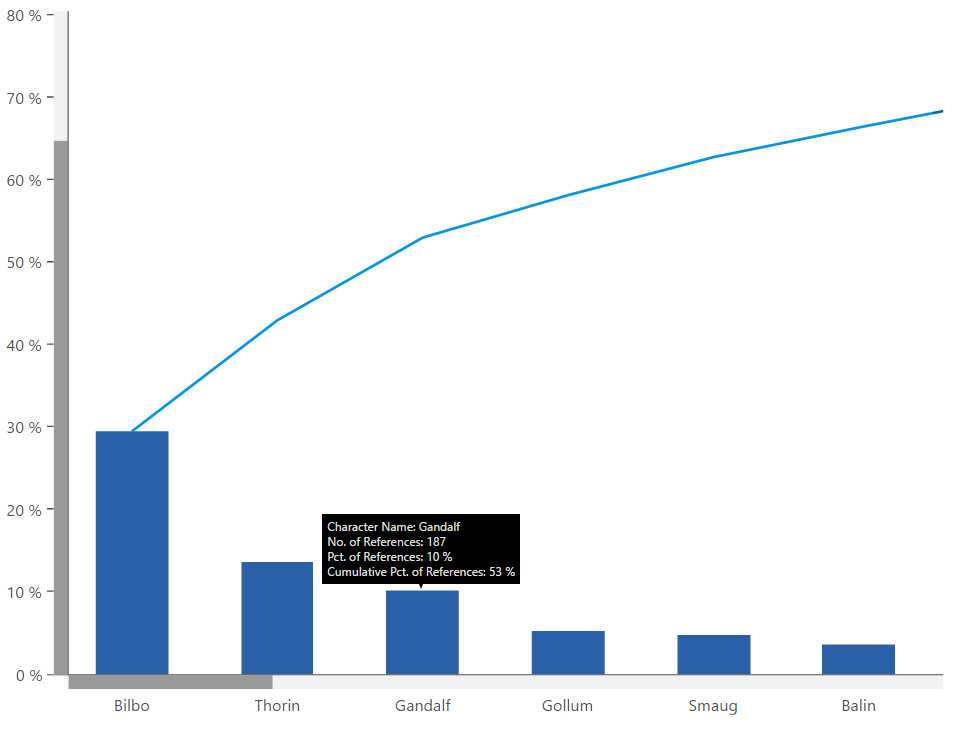
Figure 4 - Zoomed-in Pareto Chart created in Dundas BI, visualizing the frequency by which a character is referenced
The Pareto Chart does an incredibly good job of correcting a Pie Chart’s inefficiencies when it comes to understanding the share of many different items, and allows the user to make a much better claim on our hypothesis that the frequency by which a character is referenced is a strong representation of what a novel focuses on. Based on our discovery, we can easily identify which of the 26 main characters, 80% of the plot is likely centered on. In this case, we’ve identified 10/26, or 38% of the characters, which, albeit while not perfectly aligned to the 80/20 rule, is still an accurate representation of who the main characters are.
Follow Us
Support