
The Data Cube transform is created when another data cube is dragged onto the canvas. It allows you to reuse that data cube's process flow as an input to your data cube.
1. Input
The input to the other cube's process result transform is used as an input to this data cube.
2. Add the transform
Expand the data connector in the Data Cubes folder in the Explore window, then drag a different data cube to the canvas. A Data Cube transform is added.
You can optionally configure the transform by selecting the transform and clicking Configure in the toolbar or the context menu.
3. Configure
The Data Cube Transform dialog shows the original data cube's name as a hyperlink you can click to open the source cube.
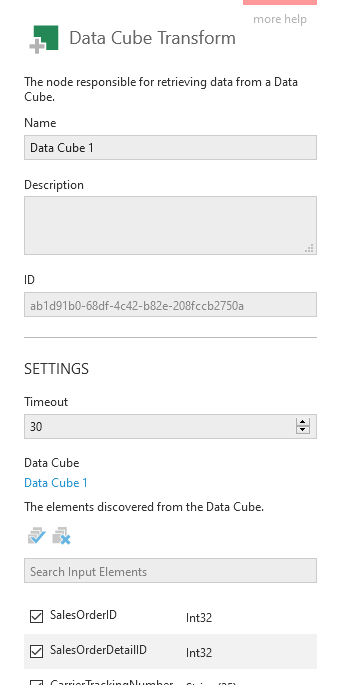
In the data cube transform itself, you can de-select input elements, set up parameters, and rename output elements, similar to other select transforms. In versions 24.3 and higher, you can add expressions if the data cube you're selecting from is using warehouse storage.
Click the submit button at the bottom of the dialog when finished.
4. Output
The Data Preview window will show the same output as shown when previewing the process result transform of the source data cube.
5. Notes
- A single source data cube cannot be used twice in the same data cube, including the entire chain of referenced data cubes (e.g., two different data cubes that reuse the same data cube cannot be combined together).
- If the source data cube is warehouse-cached, the target data cube will also be using data from the warehouse, unless a different storage type is selected for the target data cube. In contrast, if the source data cube is in-memory-cached, the target data cube will not be pulling data from memory.
- Settings in the source data cube's process result are carried over when selected in another data cube, such as hierarchies that were selected to replace 'implicit' generated hierarchies.