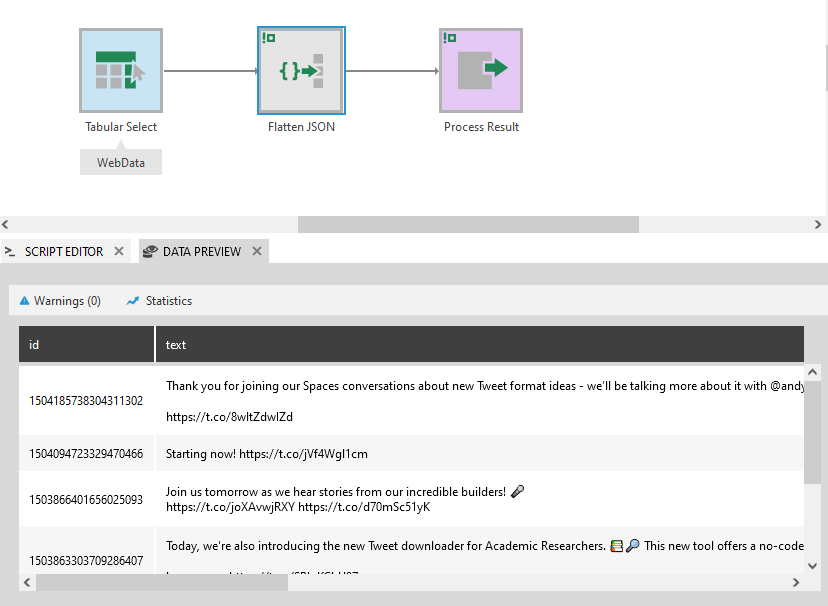
The Flatten JSON transform turns rows of data containing JSON text into separate columns for each of its values. JSON is a common result of using the Generic Web data provider to connect to online data sources, for example.
1. Input
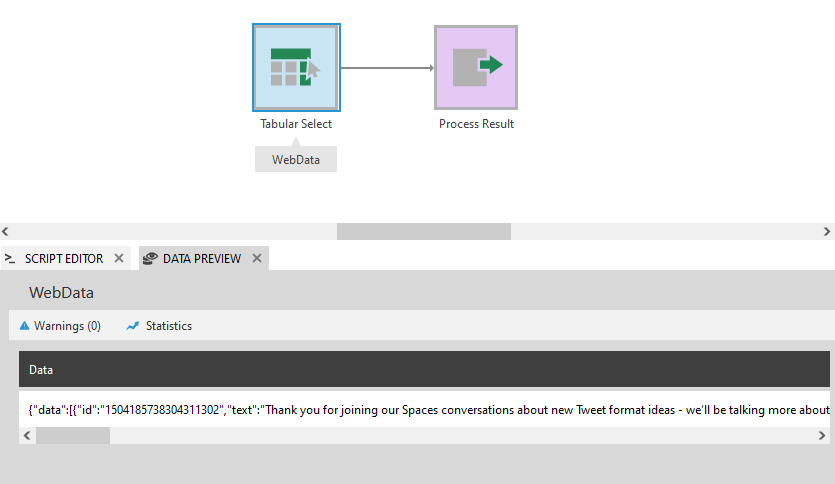
The Flatten JSON transform requires one column containing JSON text.
There might be only one row containing all of the JSON, or it could be split into multiple rows.
2. Add the transform
Optionally, click to select an existing connection between two of your transforms where you want to insert one.
In the toolbar, choose Insert Other, then Flatten JSON.
If you didn't select an insertion point earlier, click and drag from the transform you want to use as input onto the new transform to connect it.
The transform initially appears red because it requires configuration.
3. Configure
Open the configuration dialog by clicking or right-clicking the new transform and choosing Configure in the toolbar or menu (or double-clicking the transform).
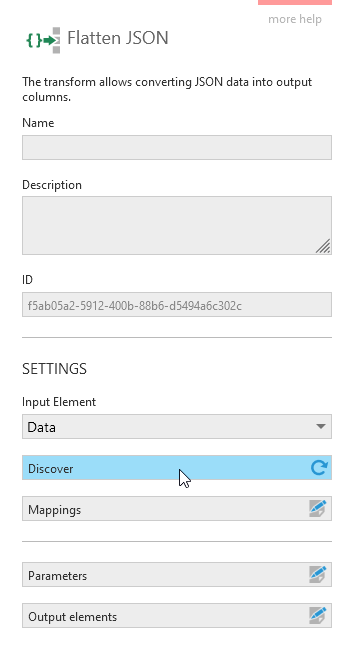
If your input has more than one column, set the Input Element dropdown to the one containing JSON text.
Next, click Discover to automatically populate mappings defining the structure and data types of your columns based on the current input JSON. A notification will appear in the lower right corner of the screen when complete, often right away.
3.1. Editing mappings
Click Mappings to confirm or change the discovered mappings, although this is typically not required.
The initial Mappings dialog shows the properties for the top level of discovered object(s) and their data types, which will be transformed into columns.
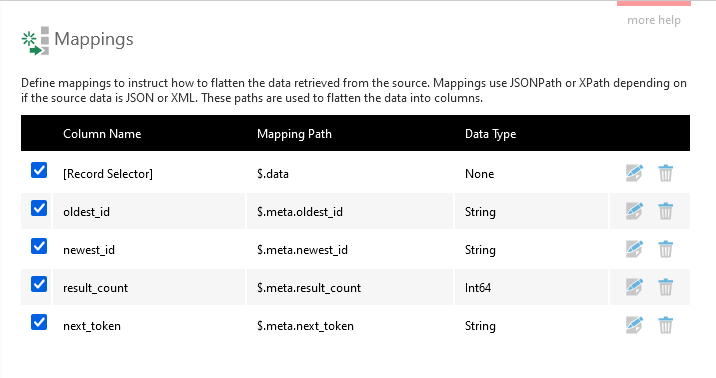
You can exclude a mapping from the transform output by unchecking its checkbox along the left, or delete it using the icon along the right.
A mapping with [Record Selector] as its column name is describing a property containing multiple child objects that will be turned into records (rows of data) and then combined/joined with the parent record. Only one of these can be enabled at the same level of mappings at a time to prevent excessive duplication of the parent record's values.
Click the Edit icon for a mapping to open its details.
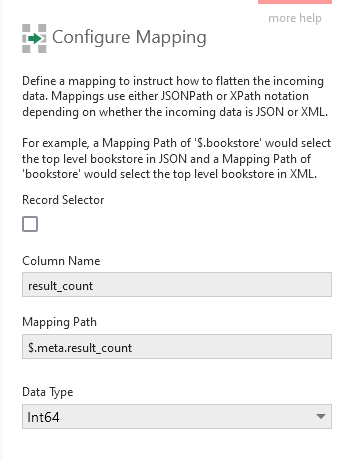
The Mapping Path is set using JSONPath syntax to refer to a property in the JSON text. For simple property values, you can change the Data Type from what was automatically discovered to another type that will be compatible with that property's values.
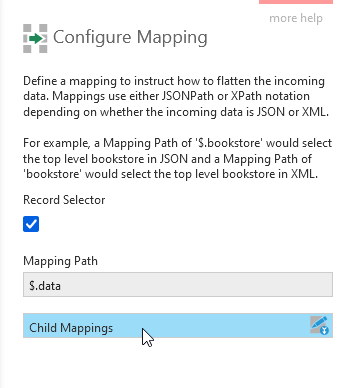
A selected Record Selector option indicates that the value of this property in JSON is an array containing child objects that will transformed into multiple records.
Click on Child Mappings for this type of mapping to open another Mappings dialog like the first one above, this time for the child object's properties.
4. Output
After submitting the configuration dialogs, you can preview the output by opening the Data Preview window with the transform selected.